Precision, Significance Level, Confidence Level, Confidence Interval, Power, Degree of Freedom, p-value,aql, z-value, t-statistics Explained
Precision: In hypothesis testing, precision means how sure we want to be before making a decision. For example, if we want to know if a new medicine is better than an old one, we need to decide how sure we want to be that the new medicine really is better. Do we want to be 90% sure, 95% sure, or 99% sure? The higher the level of precision we choose, the more sure we are before making a decision.
It refers to the level of accuracy or the margin of error that you are willing to accept in your estimate or measurement. For example, if you choose a precision level of 5%, it means that you want to be 95% confident that your estimate is within 5% of the true value.
In traditional hypothesis testing using the normal distribution, precision is not explicitly used because the significance level is used instead. The significance level determines the probability of rejecting the null hypothesis when it is actually true. It is often set to 0.05, which means that we are willing to accept a 5% probability of mistakenly rejecting the null hypothesis. The critical value or test statistic is then compared to the calculated test statistic to determine whether to reject the null hypothesis.
Significance or Significance Level: Significance level, on the other hand, refers to the probability of rejecting the null hypothesis when it is actually true. It is often set at 0.05 or 0.01, which means that there is a 5% or 1% chance of mistakenly rejecting the null hypothesis. The significance level is used to determine the critical value and the p-value in hypothesis testing.
The most common significance level used in hypothesis testing is 0.05, which corresponds to a 5% risk of making a Type I error. This means that we are willing to accept a 5% chance of incorrectly rejecting the null hypothesis and concluding that there is evidence to support the alternative hypothesis when there is actually no significant difference.
Other commonly used significance levels are 0.01 (1% risk) and 0.10 (10% risk). The choice of significance level depends on the specific research question, the consequences of a Type I error, and the desired level of confidence in the results.
Note that the precision and significance level are not explicitly used , but they are related to the confidence interval and p-value respectively. The confidence level can be set using a parameter when calculating the confidence interval, and the precision can be determined by the width of the confidence interval. The significance level can be set using the confidence parameter when performing the hypothesis test, and the p-value can be compared to the significance level to determine whether to reject the null hypothesis.
Below is a python example
=====================================
import numpy as np
import statsmodels.api as sm
# Set up example data
np.random.seed(123)
data = np.random.normal(loc=10, scale=2, size=100)
# Calculate confidence interval for mean
ci = sm.stats.DescrStatsW(data).tconfint_mean()
# Calculate p-value for one-sample t-test
t_stat, p_val, _ = sm.stats.ttest_1samp(data, 9)
# Print results
print(f"Confidence interval: {ci}")
print(f"P-value: {p_val}")
Confidence level: The confidence level is a way to measure how sure we are about our results. It's like a range of numbers where we think the true answer might be. For example, if we measure the height of a group of people and say that their average height is between 5 feet and 6 feet with 95% confidence, it means that we are 95% sure that the true average height is somewhere between 5 feet and 6 feet.
Confidence Interval: A confidence interval is a range of values that is likely to contain the true population parameter with a certain confidence level. For example, a 95% confidence interval for a population mean is a range of values that is expected to include the true population mean with 95% confidence.
Degrees of Freedom : In statistics, the degrees of freedom (df) refers to the number of independent observations in a sample or the number of parameters that can vary in a statistical model without changing the goodness of fit to the data.
For example, if we have a sample of n observations and we want to estimate the mean of the population, we can use the sample mean as an estimate. However, we can't use all n observations to estimate the variance because the sample variance involves the deviations of each observation from the sample mean, and these deviations must sum to zero. As a result, we lose one degree of freedom when estimating the variance.
Similarly, in regression analysis, the degrees of freedom represent the number of observations minus the number of parameters estimated. The degrees of freedom are important because they are used to calculate the critical values for hypothesis testing and confidence intervals.
In general, the degrees of freedom reflect the amount of information available to estimate a parameter or test a hypothesis, and they are a key concept in many statistical tests and models.
Power: Power is how well we can detect a difference if there really is one. It's like having a superpower that lets us see things that are hard to see. For example, if we want to know if a new medicine really is better than an old one, we need to make sure we have enough power to see the difference if there really is one. The higher the power, the more likely we are to see the difference if it's there.
So, in summary: precision is how sure we want to be before making a decision, confidence level is how sure we are about our results, and power is how well we can detect a difference if there really is one.
p-value: A p-value is the probability of observing a test statistic as extreme as or more extreme than the one observed, assuming that the null hypothesis is true. A small p-value (less than the significance level) suggests that the observed result is unlikely to have occurred by chance alone and provides evidence against the null hypothesis.
In hypothesis testing, we compare the p-value to the pre-specified significance level (also known as the Type I error rate), which represents the level of precision we want to achieve. The significance level is typically set at 0.05, which means we are willing to accept a 5% chance of rejecting the null hypothesis when it is actually true. If the p-value is smaller than the significance level, then we reject the null hypothesis and accept the alternative hypothesis.
in 2.5% AQL is 2.5% is precision
In a 2.5% AQL (Acceptable Quality Level), the 2.5% refers to the maximum allowable percentage of defective items in a production or sampling process. It is a standard used to measure the quality of a product or process.
The 2.5% AQL is not directly related to precision, but it does indicate the level of acceptable defectives in a sample or a production run. The precision, on the other hand, refers to the degree of accuracy and consistency in measurements or estimates.
While precision and AQL are not the same, they are both important concepts in quality control and statistical analysis. AQL sets a standard for the maximum allowable defectives, and precision measures the accuracy and consistency of measurements or estimates.
Z-statistics: It measures the standardized difference between the estimated value of mean( or proportion) and the hypothesized value of mean. Z = 3.125 implies that the sample mean is at 3.125 standard deviations away from the hypothesized population mean ( or proportion) given that the null hypothesis is true.
t-statistics: A t-statistic of 3.12 is a measure of the strength and significance of a statistical relationship or difference between two groups or variables. Specifically, it indicates the number of standard errors by which the difference between two sample means exceeds what would be expected by chance alone, assuming that the data follows a t-distribution.
In practical terms, a t-statistic of 3.12 suggests that the difference between the two sample means is quite large and unlikely to have occurred by random chance alone. The higher the t-value, the more significant the difference between the groups or variables is likely to be.
The interpretation of a t-statistic also depends on the degrees of freedom (df), which is related to the sample size. Generally, as the sample size increases, the degrees of freedom increase, and the t-value needed for significance decreases.
======================
Example
======================
Let's say we are testing the hypothesis that the mean height of a population of adult males is 6 feet (72 inches), and we want to determine if the sample data supports this hypothesis.
Confidence Interval: Suppose we collect a sample of 100 adult males and calculate their mean height to be 70 inches with a standard deviation of 2 inches. We can calculate a 95% confidence interval for the population mean height using the formula:
70 ± (1.96 * 2 / sqrt(100)) = (69.2, 70.8)
This means that we are 95% confident that the true population mean height falls within the interval (69.2, 70.8) inches.
Precision: We can also use a hypothesis test to determine if the sample data provides evidence to reject the null hypothesis that the population mean height is 6 feet. Suppose we choose a level of precision (or alpha level) of 5%. This means that we are willing to accept a 5% probability of mistakenly rejecting the null hypothesis when it is actually true. We can use a t-test to calculate the test statistic and p-value, which will tell us if the evidence supports the alternative hypothesis that the population mean height is not 6 feet. If the p-value is less than 0.05, we would reject the null hypothesis and conclude that there is evidence to support the alternative hypothesis.
Power: The power of the test depends on factors such as the sample size, effect size, and level of precision. Suppose we want to achieve a power of 80% for our test. This means that if the true population mean height is actually 71 inches (i.e., a difference of 1 inch from the null hypothesis), there is an 80% chance that the test will correctly reject the null hypothesis and support the alternative hypothesis. We can use a power analysis to determine the required sample size to achieve the desired power level, given the level of precision and effect size. For example, if we want to achieve a power of 80% with a level of precision of 5% and an effect size of 0.5 (i.e., a difference of 0.5 standard deviations from the null hypothesis), we would need a sample size of approximately 86.
In summary, confidence interval, precision, and power are three distinct but related concepts that are used in hypothesis testing and estimation. Confidence interval provides a range of values that is likely to contain the true population parameter, precision determines the level of significance at which we reject the null hypothesis, and power is the probability of correctly rejecting the null hypothesis when it is actually false.
===================
Example 2
===================
let's take an example hypothesis:
Hypothesis: A new drug reduces the incidence of a certain disease by at least 20%.
Precision: What level of precision do we want for our estimate of the reduction in incidence? Let's say we want to be 95% confident that our estimate is within 5% of the true reduction in incidence.
Significance Level: What level of significance do we want to use for our hypothesis test? Let's say we want to use a significance level of 0.05, which means we are willing to accept a 5% chance of falsely rejecting the null hypothesis.
Confidence Level: What level of confidence do we want to use for our confidence interval? Let's say we want to use a confidence level of 95%, which means we want to be 95% confident that the true reduction in incidence falls within our confidence interval.
Confidence Interval: What is the margin of error that we want to use for our confidence interval? Let's say we want to use a margin of error of 5%, which means we want our confidence interval to be plus or minus 5% of the point estimate.
Power: What level of power do we want for our hypothesis test? Let's say we want to use a power of 0.80, which means we want to have an 80% chance of correctly rejecting the null hypothesis when it is false.
Degree of Freedom: What is the appropriate degree of freedom to use for our hypothesis test? This depends on the type of test we are conducting and the sample size, so we would need to determine this based on the specific test being used.
p-value: What is the p-value that we obtain from our hypothesis test? If the p-value is smaller than our pre-specified significance level of 0.05, we would reject the null hypothesis and conclude that the new drug does indeed reduce the incidence of the disease by at least 20%. If the p-value is greater than our significance level, we would fail to reject the null hypothesis and conclude that we do not have sufficient evidence to support the claim that the new drug reduces the incidence of the disease by at least 20%.
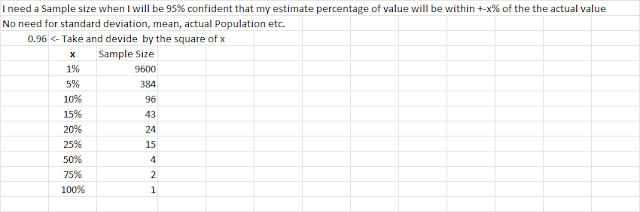
Comments
Post a Comment